
 このページでわかること
このページでわかること
- データクリーニングとはどのようなものか、どんなメリットがある作業か
- 表やテキストデータを実際にクリーニングするときのポイント
- データクリーニングのためのツールや参考資料
目次
はじめに
研究をする過程では、アンケート調査の回答、計測・観測結果など様々なデータを収集・生成することがあるかと思います。そして、そのあとには「分析」を行うことになるでしょう。
しかし、収集したデータ(仮に生データとします)をそのまま分析すると、分析に支障が出てしまうことがあります。
たとえば、アンケート調査を実施し、以下のような回答結果を分析する場合を考えてみましょう。
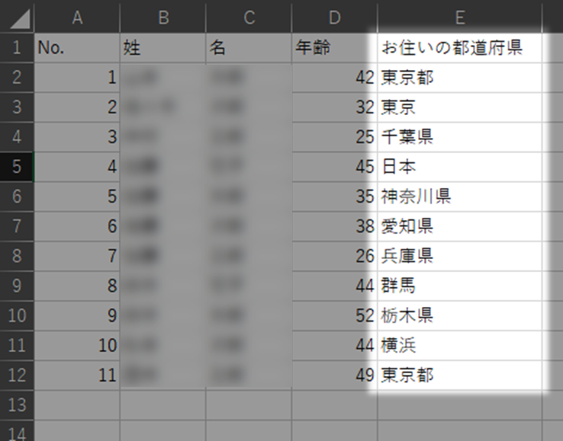
このままでは、
- 「都道府県」を末尾につけているものとそうでないものが混在している
- 誤って市区町村や国名を回答してしまっている(抽象度の異なるデータが混ざっている)
といった不備により、適切な集計を行うことは難しいでしょう。
データクリーニングとは、こういったデータの不整合や不備を修正し、分析を適切に行うための質のよいデータに整えていく準備作業です。
多くの場合、
- 値を正規化する
- 空白値の取り扱いを決める
- データを構造化する
- 分析しやすいように別の形式に整える
といった処理を行います。
ここでは、主に今までデータクリーニングを行ったことがない方を対象として、
- データクリーニングの基本的な手順
- 不備のある箇所を見つける方法
- データクリーニングに役立つツール
- 表やテキストデータを実際にクリーニングするときのポイント
について説明します。
なお、この記事では「データクリーニング」という用語で説明していますが、データの品質を向上するための行為を指して「データクレンジング」「データスクラビング」という語も用いられます。
データクリーニングのメリット
データクリーニングを行うことで、以下のようなメリットが得られます。
- データ中にあるエラーを見つけて、補正することができる
- 自分のデータをより深く理解することができる
- 効率的に正確な分析が行える
データクリーニングの準備
はじめる前に
データクリーニングを始める前に、元のファイルをコピー&ペーストしてバックアップをとっておきましょう。
こうすることで、操作を誤ってデータを消してしまったときなどに、いつでも元の状態に戻すことができます。
もしもバックアップをとっていなかった場合、最悪データ収集からやり直しになってしまう可能性もあります。
バックアップの行い方や、その際のファイル名の付け方については、以下の記事をご覧ください。
- データを適切に保存管理する① ファイル管理
※ファイル名の付け方について記載。 - データを適切に保存管理する② バックアップ
データクリーニング全般に共通する方針
データの種類や使用するソフトやツールの種類を問わず、以下の方針は共通です。
1. 元データを変更しない
はじめる前にで説明したとおり、元のファイルはコピー&ペ-ストしてバックアップをとり、直接編集しないようにしましょう。
2. 変更履歴を作成する
自分で行った操作でも、時間が経つとどんな操作を行ったか忘れてしまうものです。
自分の行った操作についてメモを取り、変更履歴を作成しておきましょう。変更履歴は、readmeファイルなどの関連する書類と一緒に保存しておきます。
3. 大きく変更を加えるときは別ファイルとして保存する
大きな変更や複雑な変更を加えるときも、事前にバックアップをして別のファイルとして保存しておきましょう。
このとき、ファイル名は「データファイル名_clean_v2.csv」のように変更して別ファイルとして保存しておくと、あとからバージョンが把握しやすくなります。
また、ファイル名だけでは、あとでなぜ別ファイルとして残しておいたか理由が分からなくなってしまうので、どこかにその理由をメモしておきましょう。
不備のある箇所を見つける
基本的には、ほとんどのデータにおいて、なんらかのクリーニング作業が必要です。
しかしながら、実際に分析をはじめるまで、なかなかそのことを実感しづらいものです。かといって、分析をはじめてからだと、クリーニング作業に戻るのは二度手間になってしまいます。
分析をはじめる前に、いくつかデータをピックアップしてチェックしたり、データを可視化したりして間違いを見つけることで、こうした二度手間を避けることができます。
分析に着手する前に、データをひと通り確認して、以下のような不備や不整合がないか確認しましょう。
- 無駄なスペース文字や改行文字がないか
- 1セルに複数の値が入っていないか
(そのままだと機械的に処理するのが難しくなるため) - 数値と文字列が混在するなど、複数のフォーマットのデータが同じ列に入っていないか
(そのままだと機械的に処理したときにエラーの原因になるため) - 太字や斜体、塗りつぶしなど見た目の編集や装飾的な情報を加えていないか
これらの不備が見つかったら、データをクリーニングする必要があります。具体的に何をどう探せばよいかについては、表形式のデータとテキストデータを確認してください。
データの可視化
「グラフ化する」「ワードクラウドを作る」など、データを可視化することで、
- 値のグループ
- 値のパターン
- 外れ値
- クリーニングが必要な値
などが視覚的にわかりやすくなり、自分のデータをより適切に理解できます。
さまざまな可視化の方法を試してみるとよいでしょう。
手軽にデータを可視化できるツールとしては以下のようなものがあります。
- Excel
- Googleスプレッドシート
- BatchGeo
住所リストを簡単に地図上にマッピングしてくれるツール。 - Voyantツール
手軽にテキストデータを可視化してくれるツールです。ツール使用時にテキストデータがサーバに送信されるため、個人情報を含むテキストで使用する場合には注意が必要です。
以下の画像は、Voyantツールにプレーンテキストを貼り付けて可視化をした例です。
具体的なクリーニングのポイント
ここでは以下の形式のデータを具体例として、データクリーニングのポイントを紹介します。
データクリーニングをどこまで・どのように行うかは、分析の方針や分析方法、用いる分析ツールによっても異なるため、ここでは基本的な確認ポイントに絞って解説していきます。
表形式のデータ(Excel、CSVなど)
Excel等の表形式のデータの入力方法については、総務省が公開している「統計表における機械判読可能なデータ作成に関する表記方法」も参考にしてみてください。
フォーマット(形式)
ファイルフォーマット
ファイルのフォーマットは、CSV(カンマ区切り)もしくはTSV(タブ区切り)で保存しておくのがおすすめです。
MicrosoftExcelなどで一般的によく使われているXLSX(Excel)というファイル形式は、研究用の分析ツールや専門の処理ソフト等では、読み込むことができない可能性があるためです。
一方、CSVとTSVはコンピュータの処理に適した(機械可読)なファイル形式なので、データ分析や可視化用のプログラムでも処理することができます。
カンマ(タブ)と改行という単純な方法でデータを表現しているため、テキストエディター等でも開くことができるなど、ソフトウェアの種別を問わず開くことができるメリットもあります。
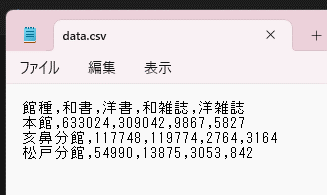
CSVをテキストエディタで開いた例
一方、CSV形式で保存した場合には、特定の値に色を付けたり、特定の値に下線などで目印をつけたり、ファイル内にグラフなどを含めたり、複数のシートを管理したりといった処理はできません。
XLSX形式のファイルは無料のMicrosoft 365 for the web等で開くことも可能ですが、長期的な保存を考えると、オープンなフォーマットであるCSVもしくはTSVで保存しておくのがよいでしょう。
保存するときにCSVかTSVかで迷ったら、より一般的に利用されているCSVの方を選択するとよいでしょう。
列のフォーマット
スプレッドシートの各列では、データの形式(数値、文字列、日付など)を統一しましょう。
ExcelやGoogleスプレッドシートでは、「数値の書式」という項目があるので、数値として扱いたい(例:計算を行いたい)データが「文字列」になっていないかなどを確認しましょう。たとえば、合計や平均などの計算を行うときに、エラーが発生することがあります。
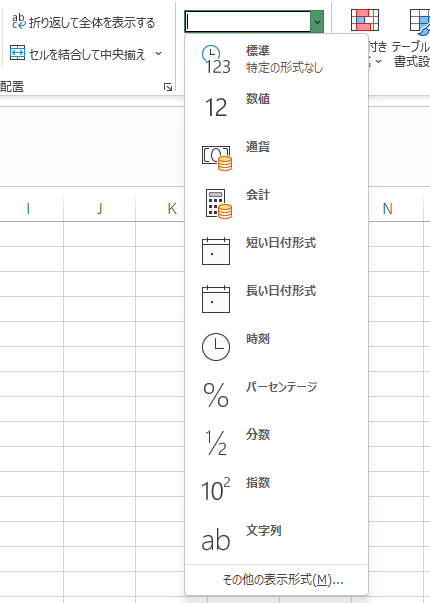
データ形式が混在し、エラーが発生する原因として、「数値と同じセルに注記(文字列)を記入してしまう、 という単純なミスが頻繁にみられます。
注記は分析する際には邪魔になるので、別の列に移動するなどして分けるようにしましょう。
日付のフォーマット
日付はYYYY-MM-DD(年-月-日)の形式で記述することをおすすめします。
こうすることで、時系列順に並び替えやすくなります。
また、
- 年を4桁で入力し表記を統一する
- 1桁の月や日は0で埋めて2桁に揃える
(例:2025年4月2日の場合、「2025-4-2」ではなく「2025-04-02」にする) - 区切り記号は「同じ記号」で入力し表記を統一する
(例:ハイフンで区切る、と決めたら、空白やアンダーバーなど「他の記号」は混ぜない)
というように、日付が一貫性のある形式で記述されていると、分析や処理がしやすいです。
なお、Excelでは1900年より前の日付を「文字列」として扱うため、注意が必要です。
「文字列」だと以下の図のように数値として集計や計算ができなくなってしまいます。
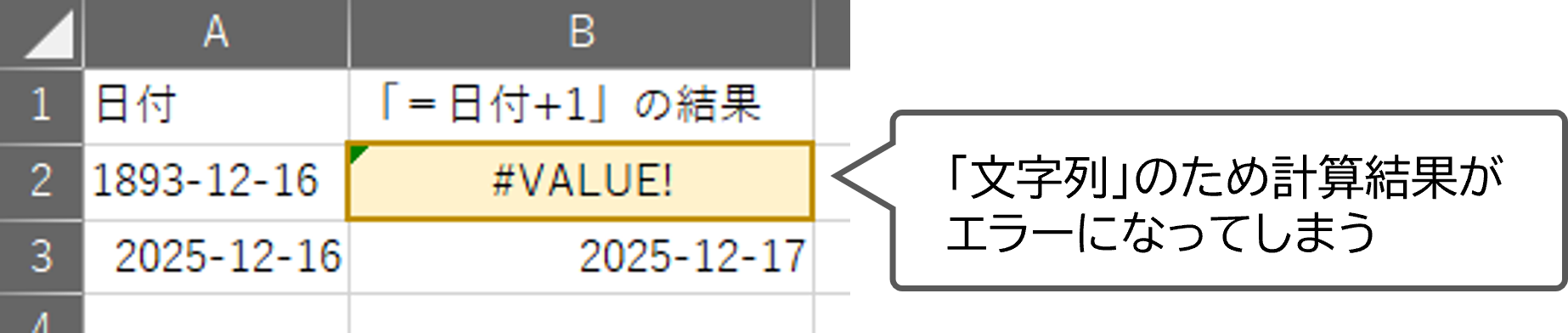
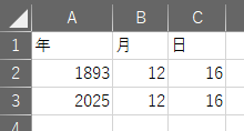
1900年より前の日付のデータがある場合は、以下のように年、月、日を別々の列に記述するのがよいでしょう。
よくあるデータの不備
ここでは、表形式のデータでよくある不備を紹介します。表形式のデータであれば、どのようなデータであっても発生する可能性があります。
重複
データを取り扱うにあたっては、各行に固有のIDを振ることがよくあるかと思います。このIDが重複していないかを確認しましょう。
Excelでは、「条件付き書式>セルの強調表示ルール>重複する値」で簡単に重複チェックができます。

重複があったときは、そのデータをより詳細に確認して、修正を行う必要があります。
たとえば、以下のような原因と修正が考えられます。
- 同じデータを別の行に分割して記録してしまった
⇒行の統合 - 同じデータを別の行に繰り返し記録してしまった
⇒行の削除 - 別のデータに同じIDを付与してしまった
⇒IDを振りなおす
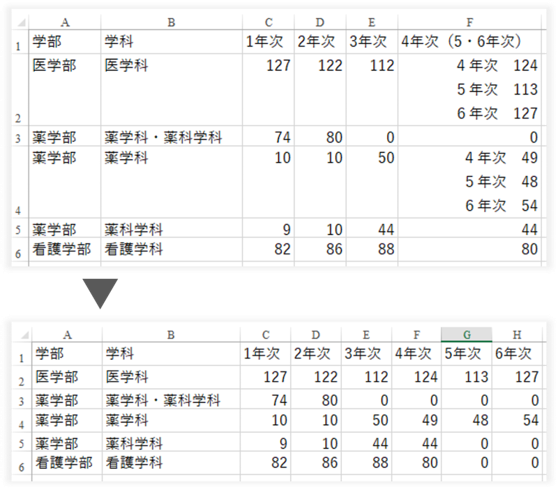
1つのセルに複数の値がある
列ごとに1種類の値、行ごとに1つのデータ、セルごとに1つの値を入れましょう。
複数の値が入ったセルはないかを確認し、もしあれば、別々の列に入れるよう修正してください。
測定単位
同じ列にある値の単位は統一しましょう。
また、単位は各セルに記載するのではなく、表頭に記載しましょう。
空白のセル
セルを空白にしておくと、その意味するところが、
- そのセルになんらかの理由で記録されるべき値が記録されなかった
(=欠損値) - そのセルに値が記録されることがない
のいずれであるかが不明瞭になってしまいます。
以下のような値を使用して、あとから確認するときにわかりやすくしておきましょう。
- N/A:Not Available=欠損値の略
- NULL:値が存在しえない
例)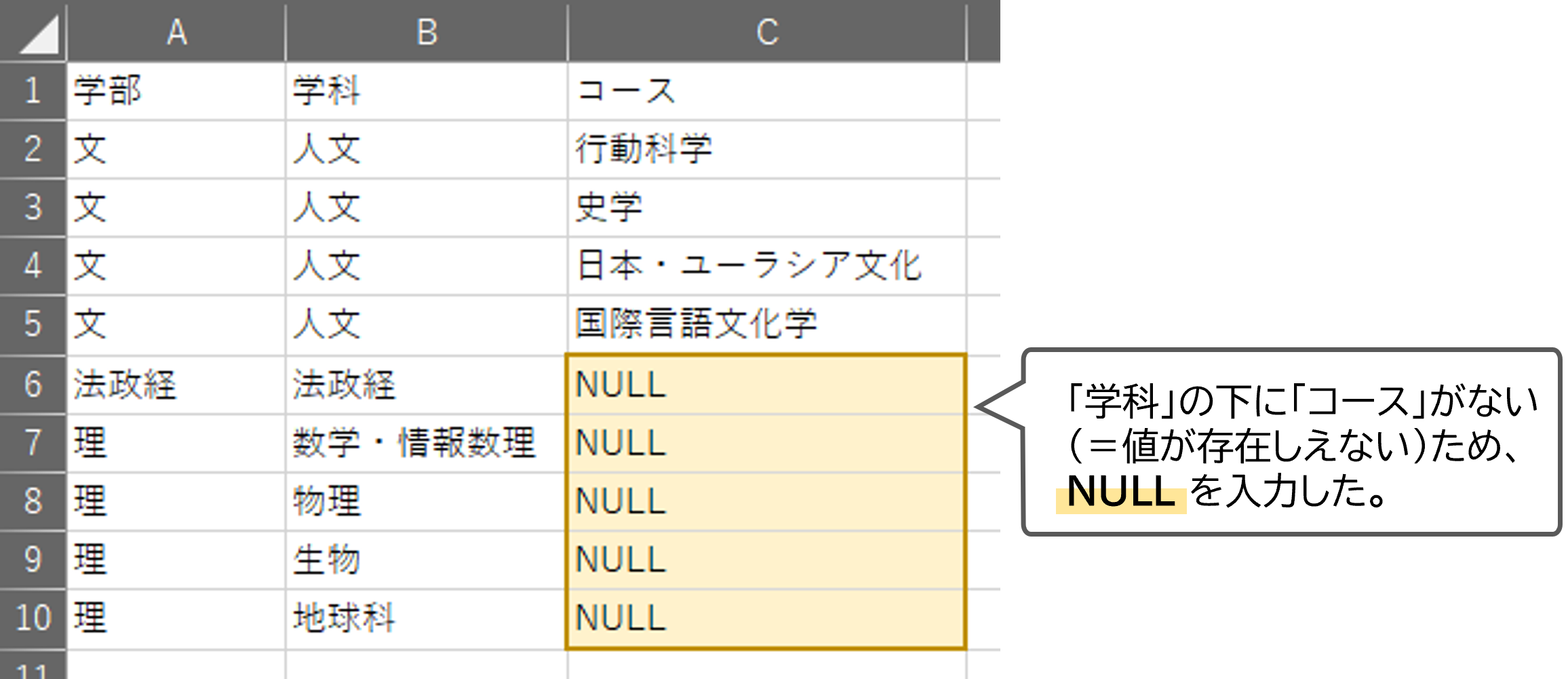
- 0
取得したデータによっては、NULL、NA、0のすべてを使用することもありえます。
もしも、自分が使用している分析ツールに推奨する値がある場合は、その値を使用するのがよいでしょう。
いずれにせよ、値はデータ内で一貫性を持たせるようにしましょう。
データの正規化
データの正規化とは、データを適正な値に整えることです。正規化を行うには、以下に示すとおり、いくつかの確認ポイントがあります。
既定値
データ形式が「文字列」の列では、既定値(はい/いいえ、多肢選択式質問、状態名など)が設定されている場合があります。
これらの列をチェックして、適正に記録されているか再確認しましょう。
たとえば、「はい/いいえ」を既定値としているのに、「Yes/No」で記録されているデータがないか、などです。
また、余分なスペースがある場合は分析の妨げになる恐れがあるため、削除しましょう。
範囲と外れ値
データの値には、あらかじめ、一定の適性とする値の範囲(ここではこれを「データの範囲」と呼びます)が設定されている場合があります。
たとえば、
- 明確な範囲が設定されているもの
例) 1~5の選択肢を設定するリッカート尺度式の質問 (データ範囲は1を下限、5を上限とする) - 多少の外れ値がありうる範囲
例) 高校生の年齢 (データ範囲は15歳を下限とし、上限には幅があるため外れ値も存在しうる)
などが考えられます。
データの範囲を調査し、最高値、最低値、平均値などを確認しましょう。
自分の想定と一致しない値を見つけたときは、データの不備なのか、それとも単に外れ値であるのかを改めて確認する必要があります。
テキストデータ(Word、.txt)
フォーマット(形式)
ファイルのフォーマットは、プレーンテキスト(.txt)がおすすめです。
分析ツールによっては、DOCX(Word)形式を読み込むことができない可能性があるためです。
プレーンテキストは、太字や下線、文字の色など見た目の情報がまったくない、テキストのみで構成されたファイルです。
一方、前述のような見た目を編集できる、Wordファイルのようなテキストを「リッチテキスト」と呼びます。
もしも、ご自身のテキストデータがWordやGoogleドキュメントなどの形式であれば、.txt形式で保存することでプレーンテキストに変換することができます。
以下の画像は、同じテキストをPDF(画像左)とプレーンテキスト(画像右)で表示した例です。

Wordファイルををプレーンテキストファイルに変換すると、太字や文字の大きさ、中央寄せ、字下げなどが表現できなくなっています。一方で、スペースや句読点、改行のような文字で表現できる範疇のことは表現できています。
プレーンテキストのメリット
- さまざまなテキスト分析・可視化ツールにも読み込める
- ファイル容量が比較的小さい
- 表示が崩れて読みづらいといった心配がない
- 無料のソフトで開くことができる
よくあるデータの不備
テキストデータにおける不備のほとんどは、「一貫性がないこと」が原因です。
たとえば、コンピュータを使って、テキストの定量分析などを行う場合を考えてみましょう。
ある研究において、テキストファイルの特定の範囲内に、特定の単語が何回出現したか?(これを「出現頻度」と言います)を調査するとします。
このとき、テキストデータのフォーマットに一貫性がないと、コンピュータは見た目が同じであっても異なるテキストデータは別の単語である (例:「全角のAI」と「半角のAI」は別の単語) と判断しているため、単語の出現頻度を調べるときに問題が起きます。
以下ではそういった不備の例を紹介します。
余分なスペース、改行、タブ
半角/全角スペースや改行、タブのような文字が単語の途中などに入ってしまっていないかを確認しましょう。
単語の途中でこういった余分な文字が入ってしまうと、分析時に一致しない語として認識されてしまう可能性があります。
既定値
テキストデータに定量的な情報が含まれる場合、既定値(はい/いいえ、多肢選択式質問、状態名など)が設定されている場合があります。
テキストをチェックして、これらが適正に記録されているかどうか確認しましょう。
たとえば、「はい/いいえ」を既定値としているのに、「Yes/No」で記入されていないか、などです。
スペリングと記号
WordやGoogleドキュメントなどには、誤字・脱字や文法のチェック機能がありますので、それを利用するのがよいでしょう。
ただし、日本語では適切に動作しないことがあったり、固有名詞などはチェックできなかったりするため、注意が必要です。
また、略称や記号(かっこや句読点など)の表記などはテキスト内で統一しましょう。
加えて、記号については、使用する分析ツールのドキュメントなども確認して、テキスト内で使用できる文字に制限がないか確認しましょう。
半角/全角の区別
英数字、記号を使用するときに、全角を使用するか半角を使用するか一貫性をもたせるようにしましょう。
そうすることで、テキスト検索で一致したものが見つけやすくなります。
半角/全角が混在していると、半角パターンの検索と、全角パターンの検索を2通り行う必要が生じ、二度手間になることがあります。
アルファベットの場合は、大文字/小文字についても同様に一貫性をもたせるようにしましょう。
テキスト内のノイズ
テキストをあるフォーマットから別のフォーマットに変換すると、予期しないノイズが生まれてしまうことがあります。
たとえば、PDFファイルのテキストをそのままコピーしたり、画像ファイルにOCR(画像等に含まれる文字を認識する技術)をかけたりすると、予期しない改行やスペースが入ることがあります。
そういったテキスト内のノイズによって、うまく分析が行えないことがあります。
テキスト内のノイズを見つけるためには、以下を確認してみましょう。
- 改行
- URL
- 単語の途中に存在する数字又は記号
- 変なところに打たれている句読点
- ルビ
- 上付き文字、下付き文字
PDFは人間にとっては問題なく読むことができるファイルですが、コンピュータによる処理には適さない(機械可読でない)ファイルとなっています。
そのため、ほとんどの場合、分析ソフトなどに読み込むことができません。
OCRによって抽出したテキストはプレーンテキスト(機械可読なファイル形式)になっていますが、その過程で前述のようなノイズが生じてしまいます。
たとえば、以下の画像は、
- PDF(画像上)
- 1.をOCRを使用してプレーンテキストに変換したデータ(画像下)
ですが、"(ダブルクォーテーション)がOCR処理テキストでは''(シングルクォーテーション2つ)に置き換わっています。

データクリーニングではこういったノイズを取り除く必要があります。
データクリーニングツールと参考情報
データクリーニングツール
表形式データ
OpenRefine
Excelでの処理が煩雑になるくらいデータ量が多かったり、それに伴って不備が多かったりする場合は、OpenRefineを利用するとよいでしょう。
OpenRefineは、表記ゆれなど表形式のデータでよく起こる不備を特定して補正してくれる、無料のデータクリーニング用ツールです。
詳しい使い方などは、以下の資料をご覧ください。
- OpenRefine Libguides(英語)
イリノイ大学が提供しているOpenRefineの使い方ガイドです。
Excel
OpenRefineほどではありませんが、Excelでもデータクリーニングを行うことができます。
ただ、Excelでは操作を誤りやすいため、変更の必要がないセルをロックしたり、既定値のあるデータには「データの入力規則」を適用したりするとよいでしょう。
- Microsoftのチュートリアル
- データをクリーンアップする方法トップ10
Excelでデータをクリーニングするときに役立つ機能などを紹介しています。 - セルをロックしてExcelで保護する
誤ってデータを消したりしてしまわないためにセルをロックする(=編集できなくする)方法を紹介しています。 - セルにデータの入力規則を適用する
データのフォーマット(形式)を統一したり、値を正規化したりするために、セルに入力規則を設定する方法を紹介しています。
- データをクリーンアップする方法トップ10
- はじめてのデータ集計
Excelを使用してデータを集計する方法を解説した動画です。「データ集計の準備」でデータクリーニングに通ずる内容を取り扱っています。
Google スプレッドシート
Googleスプレッドシートでは、列の分割、重複の排除、余分なスペースの削除といったことが行えます。
GoogleスプレッドシートはデータをGoogleドライブに保存することになるため、センシティブデータなど一部のデータでは使用を避ける必要があるかもしれません。
センシティブデータを取り扱う場合は、ExcelやOpenRefineなどPCのローカル上で動作するソフトウェアを利用した方がよいでしょう。
テキストデータ
正規表現
正規表現とは、「メタ文字」という特殊な文字を用いるなどの方法で、高度な文字列の検索や置換を行う仕組みのことです。
Wordやテキストエディタにある通常の検索機能では、ある特定の単語しか検索できません。しかし、正規表現を用いれば、数字・スペース・タブ・改行・句読点といった特定の種類の文字や、電話番号・日付・URLといった規則性のある文字列を検索することができます。
正規表現を使用できるツールとしては、以下のようなものがあります。
- Googleドキュメント
検索と置換のページにおいて、Googleドキュメントでの正規表現の使用方法や利用できるメタ文字などについて説明があります。 - サクラエディタ
Windowsにインストールできる日本語のテキストエディタです。
正規表現の使い方などについては、以下の資料をご覧ください。
- 検索と置換 | Googleドキュメントエディタヘルプ
上でも紹介したページです。正規表現を使用した検索と置換の例が掲載されています。ここでの事例はGoogleドキュメントに限らず、他のテキストエディタでもおおむね利用できる事例です。 - サクラエディタで利用可能な正規表現
サクラエディタで使用できる正規表現の一覧です。
そのほか、正規表現の実例については、インターネット上でさまざまな紹介がされているので、調べてみましょう。
参考情報
データクリーニングについてもっと詳しく学びたい方は、以下の資料を確認してみましょう。
- 初心者向けテキストマイニングに関する書籍
KH Coder(有償)というソフトウェアを使ったテキスト分析に関する書籍です。書籍に沿って使い方を学ぶ場合に限り、無料版でも行えます。 - The Programming Historian日本語訳
国文学研究資料館が公開しているページ。OpenRefine及び正規表現によるテキストクリーニングに関する記事がある。 - バッドデータハンドブック
データに関する不備とその修正方法などが掲載されています。ただし、UNIXのコマンドラインなどを扱うため、今回の記事よりも発展的な内容になっています。
わからないことがあったら
分野別学習相談では、千葉大学の大学院生(ALSA-LS)に、学習・研究上の悩みや課題・レポートについて相談することができます。
相談できる分野に統計・データ処理があるので、わからないことがあったら相談してみてください。
くわしくは、学習上の悩み・課題・レポートについて相談する(分野別学習相談)のページをご確認ください。
この記事は、イリノイ大学のData Cleaning for the Non-Data Scientistを翻訳し、一部改訂を加えたものです。